Image Recognition Using Raspberry Pi
In this project, I use Raspberry Pi and TensorFlow to train the computer to interpret images of common objects and classify them. After analyzing the image, the Raspberry Pi will output the subject of the image to the user, providing a range of possible outputs and the chance of the image being each of the listed possibilities. My specific goal is to use the program to analyze models of chemical compounds and output the name of the compound to the user.
| Engineer | School | Area of Interest | Grade |
|---|---|---|---|
| Advaith M. | Archbishop Mitty High School | Computer Science/Electrical Engineering | Incoming Senior |


First Milestone
My first milestone was setting up the Raspberry Pi with the appropriate operating system and monitor, as well as writing the code in the terminal to complete basic image recognition of simple images. Using TensorFlow and Python, I was able to download all the necessary modules which contain files that carry out the process of image recognition. Following this, I trained the Pi with a simple image of a panda and it was able to produce a list of potential outputs of the animal which could be in the image, with the panda receiving the highest probability. However, the Raspberry Pi ran out of storage, so I continued the project on a Macbook. Towards the end of the project, I will transfer the model to the Pi, which will perform the classification.
 {:target=”_blank” rel=”noopener”}
{:target=”_blank” rel=”noopener”}
Second Milestone
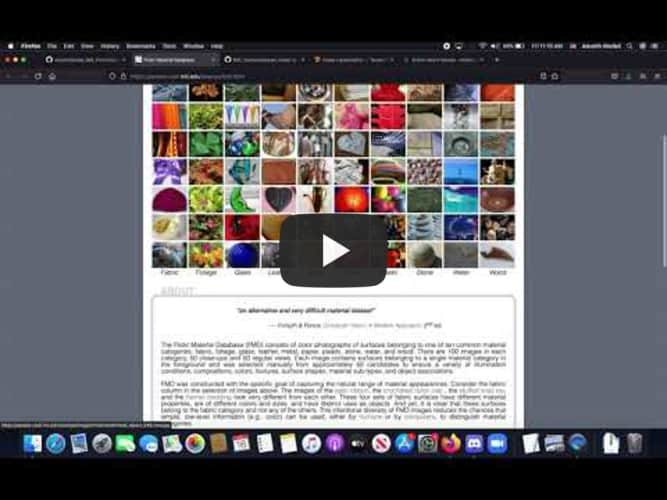
My second milestone was to use a dataset and import it into the terminal of my computer to start using it to train a model capable. At first I chose a dataset with over 4.4 million files of known chemical compounds, with the goal of using a trained model to interpret the image and output the name of the compound to the user. However, due to the size of the dataset, I was unable to use the trained model to classify the images. To fix this issue, I used an already existing dataset (https://people.csail.mit.edu/lavanya/fmd.html). This dataset consists of images of everyday objects, such as leather, glass, and fabric, with each general class having about 100 images. In the next milestone, my goal is to use the new dataset and train a model capable of image recognition. Ultimately, the final product will be transferred to the Raspberry Pi using a feature in TensorFlow.
Final Milestone
My final milestone was to use a neural network to interpret the images from the dataset and output the class of the images to the users. This was a very exhausting process, requiring me to invest a lot of time in researching which pre-processing algorithms to use. I also had to use each neural network in my code to make sure I settled for whichever yielded the highest accuracy. Initially, I used the VGG16 and VGG19 convolutional networks to train my dataset, but both yielded very low accuracy values, between 9 and 10 percent. To fix this issue, I attempted to alter the specific parts of the neural network hidden layers that impact the interpretation of the images, by changing the numbers of layers that were used, as well as the learning rate. However, these changes did not produce a higher accuracy. Fortunately, I was able to find a much more efficient model, the MobileNet V2, which gave me much higher accuracy values, reaching 65%. Although this is not the highest, the trained model was able to accurately interpret a majority of the images.
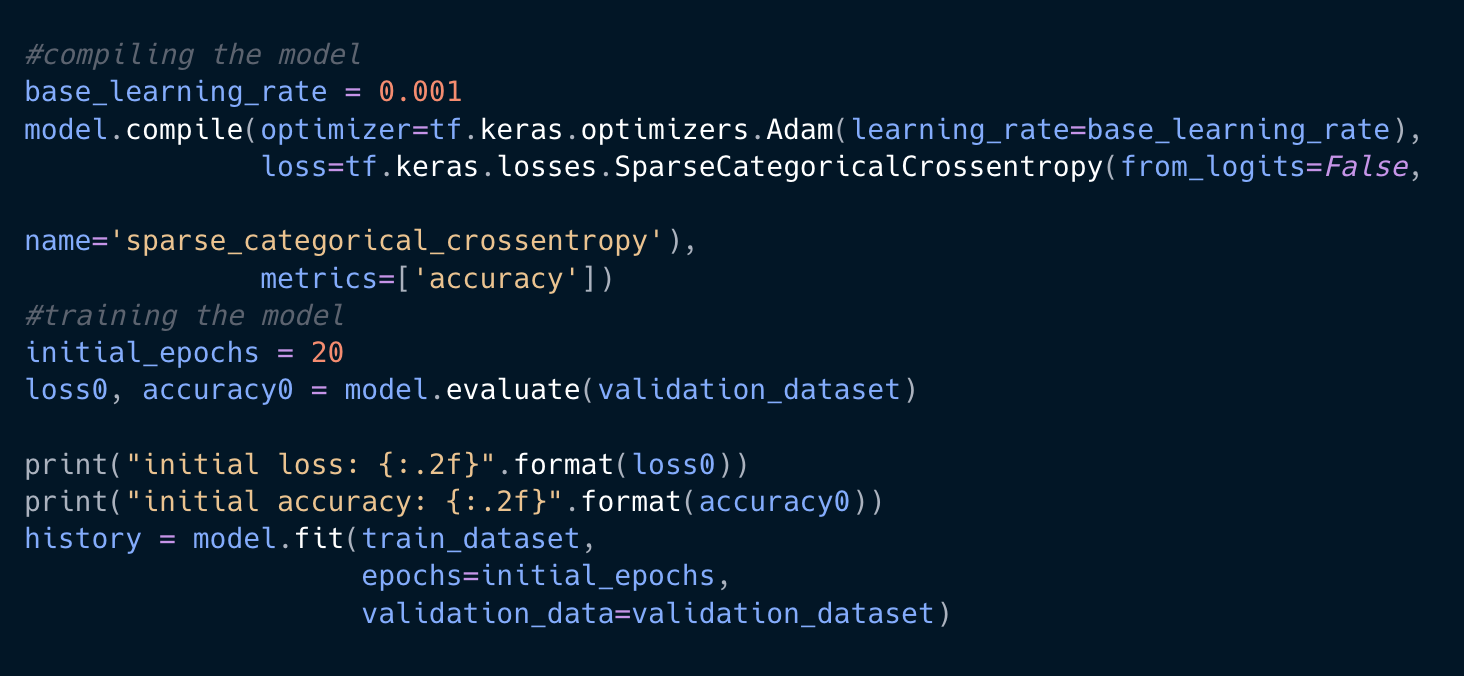
Here is some of the code that I used to create a model to train the dataset:
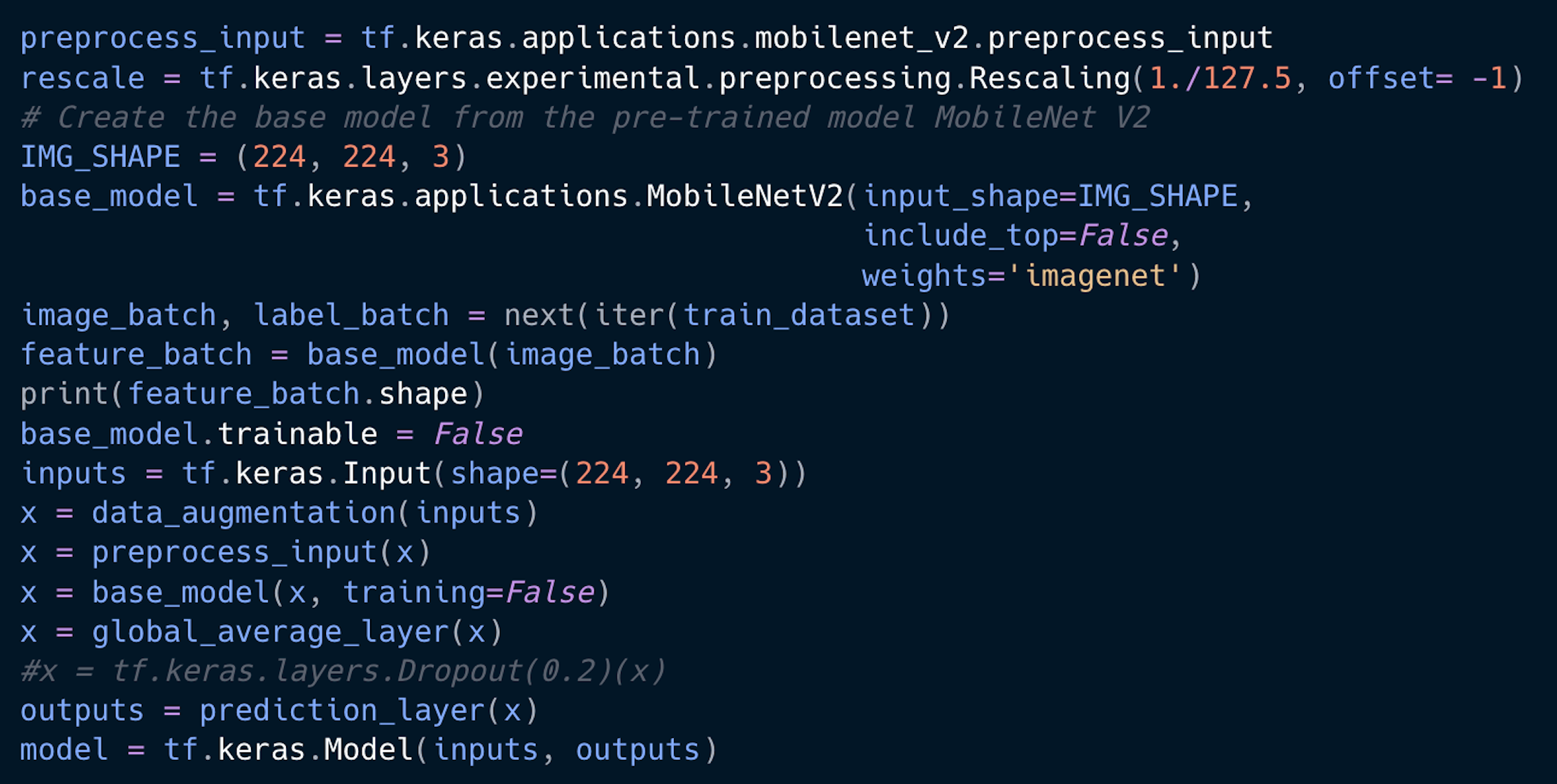
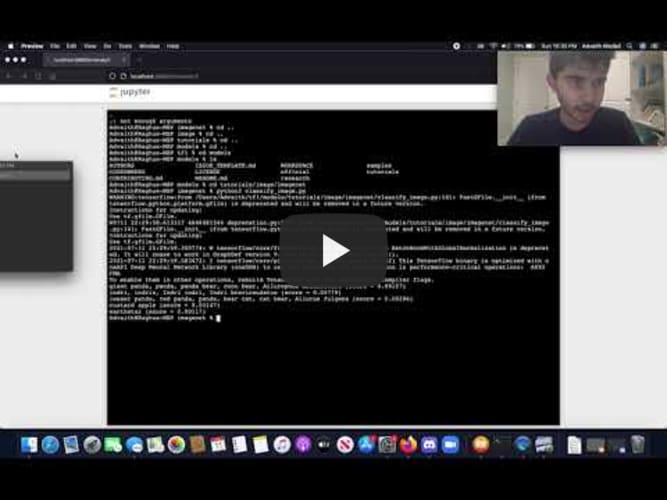
Here is how I trained the dataset: